
Advanced Backup Solution SIEM Alerts:
We are going to start by finding normal. We need to baseline our backups. How can we do that?! So long as you are using some sort of backup account, and the authentication logs are in Graylog. Simply, the prerequisites are authentication logs for your backup account are in Graylog. After that, we just need to spend some time to figure out what the account(s) are doing. Further, we should be documenting these things as we go throughout this process. Now, if you have another SIEM solution that is okay too. So long as you can convert these queries, or your SIEM solution can find these item(s), then you should be able to follow along with the general idea of what we are doing here, but know some of these things other SIEMs may not be able to do entirely, the big players should be fine though.
Let’s dive right in!
Technical:
Start by finding normal. What user account are you using to perform your backups? Let’s say our account is named “Veeam” because we are using Veeam backups. So we will want to start with a query such as:

Take a look at your results for the time frame you selected. This query is very, very basic right? It has a lot of noise, but gives us a general idea of a starting point. Nothing much to document here just yet.
Next, lets go a bit deeper. Let’s do:
user_name:veeam AND event_code:4624
- This above search will give you the results of the windows event ID 4624 + the user account we are focusing in on. What helps define normal? We have to discover this, but how? Ask questions such as:
- How often is this account logging in every 24 hours?
- How many of those are successful?
- How many failures?
- Show top values on each field:
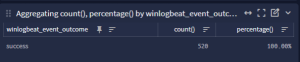
So now we are only seeing the successful logons for that account, for whatever time period you are reviewing. Document the above answers to the questions you asked. Keep these handy.
Track down your failure(s) *event_code:4625 = failed*. Why did those happen? Document these. Are there a high number of failures? What is causing those? Is it a script, or is it trying to log into something it should not, or no longer exists? Spend time to track down your failures, and eliminate as many of those as you reasonably can. This is going to help you later. If you are unsure how to track these down, keep reading on. You can come back to this once we dig into the successes further, and it should shed some light on how to dig a bit deeper into those. We want high fidelity alerts right? Did you think this was going to be easy? Put alert in place and done right? This is not the case, but this is generally not terrible to chase down either for a very high quality alert.
Back to the successful logons and baselining:
Next question:
- What logon type does this account use?
- What is the highest volume for type of logon for this account? (*hint, should be type 3 network, all others should be investigated)
- Show top values on this field as well:
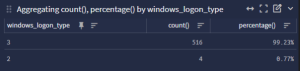
The above shows us that there is two logon types being used by our Veeam account (Type 2 *interactive, and Type 3 *Network). We should really only see Type 3 for the most part. These were me interactively logging into that account for the purposes of this guide to show that. Sometimes to troubleshoot a backup, the backup admin or the responsible party will log into a server using that account. That is where you should see those come from legitimately. Otherwise, you really should not see those unless you are using your backup to backup an application. Those can cause an interactive logon to happen as well. So keep that in mind. Also, remember let the corner case be the corner case. Do not allow the exception to become the rule.
Now, what logon package is used?
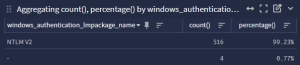
Make sure to question your return data. If this is NTLMv1 for example, then maybe that gives you some idea that you need to do some OS hardening? Keep in mind, just because it is happening, does not mean it should be happening. But now for purposes of this guide we know that it is mostly NTLMv2 which is fine. Great!
Now we need to figure out source IP / hostname so we can baseline where the logons are coming from. What source is the account logging into the devices to create the backups from!?
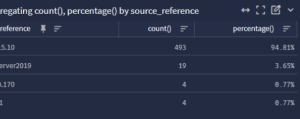
We need the source device name(s) and IP address(es) that are likely the Veeam servers. If you see any device(s) that are not backup servers here, you should really question/scrutinize those device(s) at this time. These could be somehow normal? Or they could be compromised device(s) on your network that are performing reconnaissance against your network.
What can we do with all of this information now?!
- Scrutinize it. Is this information correct? Do all of those IP address(es) line up with devices you would expect Veeam to logon to machines as? Any anomalies? Investigate them. Look at those device(s) historically. Is this a one off? Was someone troubleshooting something with the Veeam account? Is there something happening that really should not be, or is there misuse of that account!?
- After getting your questions answered, you have now defined normal. You have been taking notes this whole time right? You placed all of this information into a knowledge base article correct? Nudge, nudge.
- Next we take our current notes, and start expanding our search out broader, and broader. Is our current notes correct across a broader set of time? If not, why not? further investigation needs to occur here. Once we have truly baselined those items we are most interested in, we need to figure out what our allowances should be for some of them.
Here is an example:
- Network Logons have been tracked down, and we only see Type 3 (Network) now.
- IP addresses have been tracked down, and we should only see 5 devices:
- Two IP Addresses, and two Server names, and maybe a loopback address here or there.
- All logons are successful, and our current average per 24 hours is 520 successful logins every 24 hours
- NTLMv2 should be in in those logs now, and we should see a matching number of those to the successful logons. (520)
- Domain name (I know this one seems silly right now): all logs have the right domain name as part of their authentication events.
- We ask the question and in our demo, we have 52 servers, each being backed up 10 times per day. Does this match our current Veeam backup schedule? Yes, it does in our demo scenario.
Now what?! Let’s write an alert! Finally! sheesh!
- If we have done everything correctly, then this alert should have a “High Priority”.
- This alert looks at the following baselined items:
- The appropriate Logon type (3)
- The appropriate logon source(s) (Insert IP Addresses, and source reference names)
- The appropriate logon
- The appropriate domain name (domain name)
- The appropriate volume of logons for this account in general. (520)
- Lets start with a simple volume threshold logon for a 24 hour period:
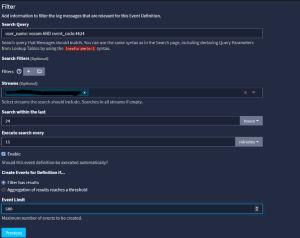
We do not want to make the the alert for 520, because that would almost always go off. What is the first step of troubleshooting for a backup admin?! Re-run the job. You will have lots of false positives for that. But maybe we make a 10% – 15% threshold that allows for that. Then we will be alerted less often for failed backup troubleshooting. You can experiment here with your specific environment, and how often your backups fail. 5% may be a better tolerance, or 20% may be a better tolerance. It comes down to your environment.
Next, lets do the opposite now. Let’s put an alert in place for failed logons for this account based around the documented failure rate threshold to your environment. Same thing, just using event_code:4625.
Next, let’s create an alert for this account again, but for NTLMv2 using the following query (or specific to your environment)
user_name:veeam AND event_code:4624 AND NOT windows_authentication_lmpackage_name:”NTLMV2″
Let’s do the same thing, but this time for logon type. You may have to set your thresholds appropriately to your environment.
user_name:veeam AND event_code:4624 AND NOT windows_logon_type:3
Let’s make yet another alert for the appropriate domain name (if applicable):
user_name:veeam AND event_code:4624 AND NOT source_user_domain:{domainhere}
How about another one for the appropriate source(s) for your account to log in from:
user_name:veeam AND event_code:4624 AND NOT (source_reference: 127.0.0.1 OR source_reference:10.10.10.10 OR source_reference:veeam)
Some notes to keep in mind, as you add new servers you will need to update your baseline(s), thresholds, and alerts. To keep these high fidelity alerts, you will have to maintain them. They will stay high fidelity as long as your network stays clean, your documentation stays clean, and you keep them clean. You can write the above alert(s) in more complex fashions as well, but I went simple to keep this easy/straight forward. Also, if you get too complex, you will have to dig into why this alert specifically went off. Sometimes that is more work than adding individual alerts up front. If you have 3 alerts covering everything above, you will have to figure out the reason they were triggered, via an investigation. Further, if you have alterations, you may only have to adjust one of them, or you may have to adjust all. YMMV based upon your environment.
Lastly, what we just did here, will work with nearly any accounts. Service accounts, high risk user accounts, etc. Understanding and baselining your user base can give you insight and visibility into your environment in ways that will enable you to go further than you ever imagined.